Optionen für Wiederherstellungsstandorte und Ausfallsicherheit der Infrastruktur
Wiederherstellungs Standorte sind vordefinierte Orte, an die eine Organisation ihre kritischen Abläufe im Falle einer größeren Störung oder Katastrophe verlagern kann. Die Wahl des Standorts hängt vom Budget, den Wiederherstellungszeit Zielen und den Wiederherstellungspunkt Zielen der Organisation ab:
- Heiße Standorte
Dies sind voll funktionsfähige Rechenzentren, die mit der gesamten erforderlichen Hardware und Software ausgestattet sind und die Haupt Betriebsumgebung spiegeln. Sie bieten sofortige Failover-Fähigkeit und minimieren die Ausfallzeiten. Hot Sites sind die teuerste Option, bieten aber die schnellste Wiederherstellungszeit.
- Warme Standorte
Diese Einrichtungen sind teilweise mit Netzverbindungen und Servern ausgestattet, beherbergen aber in der Regel keine Live-Daten oder aktuelle Anwendungen. Im Falle einer Katastrophe braucht ein warmer Standort einige Zeit, um betriebsbereit zu sein, da Daten und Software geladen werden müssen, um die volle Funktionalität zu erreichen. Warme Standorte stellen einen Mittelweg in Bezug auf Kosten und Geschwindigkeit der Wiederherstellung dar.
- Kalte Standorte
Cold Sites bieten nur den physischen Raum für Wiederherstellungsvorgänge; sie enthalten keine vorinstallierte Hardware oder Software. Unternehmen, die einen Cold Site nutzen, müssen Geräte installieren und konfigurieren und Daten aus Sicherungskopien wiederherstellen, was die Wiederherstellungszeit erheblich verlängern kann. Cold Sites sind die kostengünstigste Option, erfordern jedoch den größten Aufwand bei der Einrichtung nach einer Katastrophe.
Beim Aufbau einer widerstandsfähigen Infrastruktur geht es darum, sicherzustellen, dass IT-Systeme, Netzwerke und Dienste Ausfällen oder Störungen standhalten und sich davon erholen können:
- Redundante Systeme:
Die Implementierung von Redundanz beinhaltet die Schaffung von Duplikaten kritischer Komponenten oder Systeme, wie z. B. Server, Netzwerke und Datenspeicher, um sicherzustellen, dass im Falle eines Ausfalls Zusatzoptionen zur Verfügung stehen. Dies kann mehrere Stromquellen, Netzwerkpfade und Rechenzentren umfassen.
- Failover-Mechanismen:
Failover bezieht sich auf die automatische Umschaltung auf ein redundantes oder Standby-System bei Ausfall oder anormaler Beendigung der zuvor aktiven Anwendung, des Servers oder des Systems. Dieser Prozess trägt zur Aufrechterhaltung der Dienst Kontinuität ohne menschliches Eingreifen bei.
- Skalierbare Lösungen:
Die Infrastruktur sollte so konzipiert sein, dass sie unterschiedlichen Belastungen standhält und je nach Bedarf nach oben oder unten skaliert werden kann. Durch die Skalierbarkeit wird sichergestellt, dass die Infrastruktur das Unternehmenswachstum unterstützen und sich an Änderungen anpassen kann, ohne dass eine vollständige Neugestaltung erforderlich ist.
- Regelmäßige Tests:
Regelmäßige Tests der Widerstandsfähigkeit der Infrastruktur sind von entscheidender Bedeutung, um sicherzustellen, dass die Systeme im Falle einer Störung wie erwartet funktionieren. Dazu gehören die Simulation von Ausfällen und das Üben von Wiederherstellungsverfahren, um etwaige Schwachstellen zu ermitteln und zu beheben.
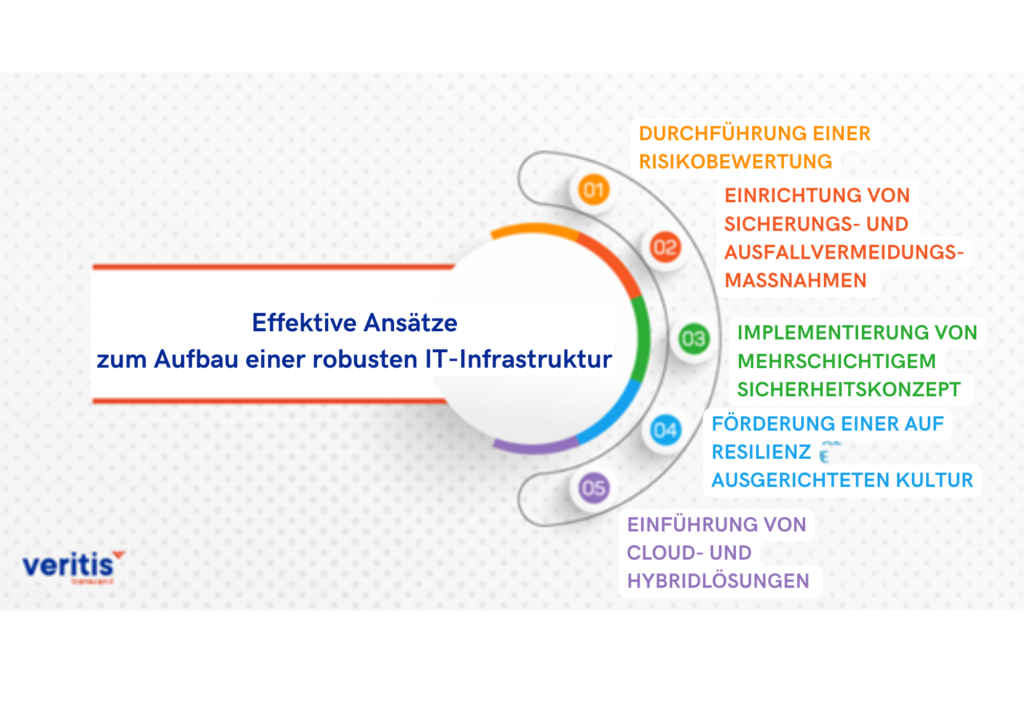
Abbildung -7
(Ressource: https://www.veritis.com/blog/building-a-resilient-it-infrastructure-with-business-continuity-and-disaster-recovery/)