Opzioni del sito di ripristino e resilienza dell’infrastruttura
I siti di ripristino sono luoghi predefiniti in cui un’organizzazione può trasferire le proprie operazioni critiche in caso di gravi interruzioni o disastri. La scelta del sito dipende dal budget dell’organizzazione, dagli obiettivi di tempo di ripristino (RTO) e dagli obiettivi di punto di ripristino (RPO):
- Siti “caldi” (hot site)
si tratta di centri di dati pienamente operativi, dotati di tutto l’hardware e il software necessari, che rispecchiano l’ambiente operativo principale. Offrono una capacità di failover immediata, riducendo al minimo i tempi di inattività. I siti caldi sono l’opzione più costosa, ma offrono i tempi di ripristino più rapidi.
- Siti “tiepidi” (warm site)
queste strutture sono parzialmente dotate di connessioni di rete e server, ma in genere non ospitano dati in tempo reale o applicazioni aggiornate. In caso di disastro, un sito “tiepido” richiede un certo tempo per diventare operativo, poiché i dati e il software devono essere caricati per raggiungere la piena funzionalità. I siti “tiepidi” rappresentano una via di mezzo in termini di costi e velocità di ripristino
- Siti “freddi” (cold site)
siti “freddi” forniscono solo lo spazio fisico per le operazioni di ripristino; non includono hardware o software preinstallati. Le organizzazioni che utilizzano un sito “freddo” dovranno installare e configurare le apparecchiature e ripristinare i dati dai backup, il che può allungare notevolmente i tempi di ripristino. I siti “freddi” sono l’opzione meno costosa, ma richiedono il maggior impegno per la configurazione dopo un disastro.
Costruire la resilienza dell’infrastruttura significa garantire che i sistemi, le reti e i servizi IT possano resistere e riprendersi da guasti o interruzioni:
Sistemi ridondanti: l’implementazione della ridondanza comporta la creazione di duplicati di componenti o sistemi critici, come server, reti e archiviazione dati, per garantire la disponibilità di opzioni di backup in caso di guasto. Ciò può includere più fonti di alimentazione, percorsi di rete e centri dati.
Meccanismi di Failover: per failover si intende il passaggio automatico a un sistema ridondante o di riserva in caso di guasto o di interruzione anomala dell’applicazione, del server o del sistema precedentemente attivo. Questo processo aiuta a mantenere la continuità del servizio senza l’intervento umano.
Soluzioni scalabili: l’infrastruttura deve essere progettata per gestire carichi variabili ed essere in grado di aumentare o diminuire secondo le necessità. La scalabilità garantisce che l’infrastruttura possa supportare la crescita dell’azienda e adattarsi ai cambiamenti senza richiedere una riprogettazione completa.
Test regolari: testare regolarmente la resilienza dell’infrastruttura è fondamentale per garantire che i sistemi funzionino come previsto durante un’interruzione. Ciò comporta la simulazione di guasti e la pratica di procedure di ripristino per identificare e risolvere eventuali punti deboli.
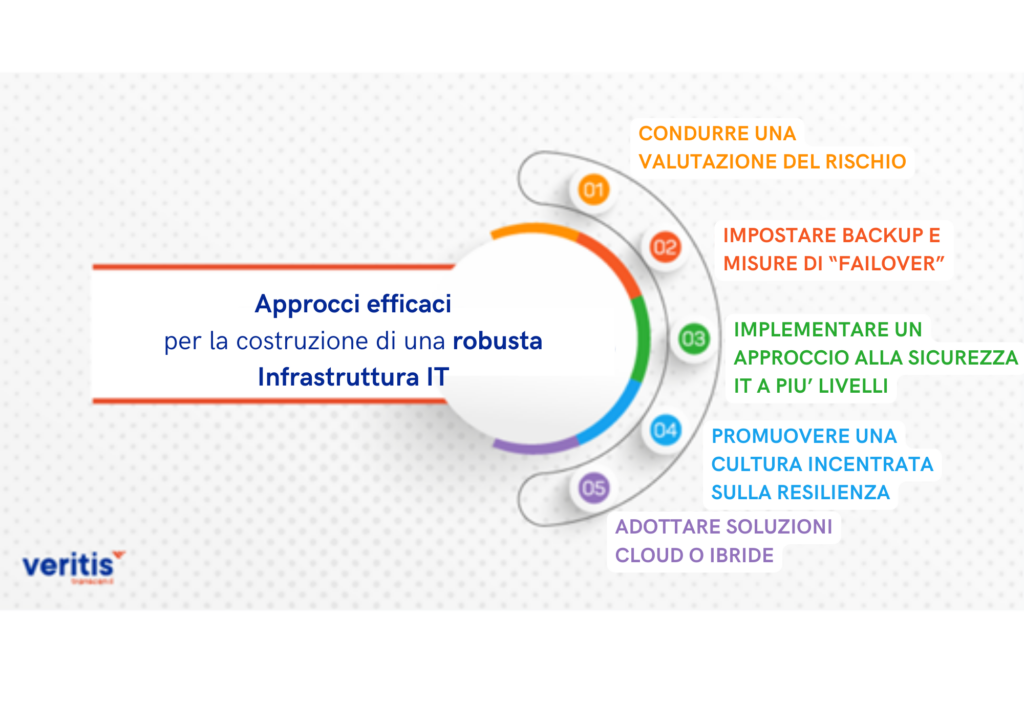
Figura-7